Redis 的集群节点之间的通信采取 gossip 协议进行通信,在 redis cluster 架构下,每个 redis 要放开两个端口号,比如一个是 6379,另外一个就是 加10000 的端口号,比如 16379,16379 端口号是用来进行节点间通信的。
Gossip协议
Gossip protocol 也叫 Epidemic Protocol (流行病协议),顾名思义,就像流言蜚语一样,利用一种随机、带有传染性的方式,将信息传播到整个网络中,并在一定时间内,使得系统内的所有节点数据一致。这里简单介绍下Gossip协议的执行过程:
当一个种子节点有状态需要更新到网络中的其他节点时,它会随机的选择周围几个节点散播消息,收到消息的节点也会重复该过程,直至最终网络中所有的节点都收到了消息。
Gossip协议优势:
- 扩展性 网络可以允许节点的任意增加和减少,新增加的节点的状态最终会与其他节点一致。
- 容错 网络中任何节点的宕机和重启都不会影响 Gossip 消息的传播,Gossip 协议具有天然的分布式系统容错特性。
- 去中心化 Gossip 协议不要求任何中心节点,所有节点都可以是对等的,任何一个节点无需知道整个网络状况,只要网络是连通的,任意一个节点就可以把消息散播到全网。
- 一致性收敛 Gossip 协议中的消息会以一传十、十传百一样的指数级速度在网络中快速传播,因此系统状态的不一致可以在很快的时间内收敛到一致。消息传播速度达到了 logN。
- 简单 Gossip 协议的过程极其简单,实现起来几乎没有太多复杂性。
Gossip协议的缺陷:
- 消息的延迟 由于 Gossip 协议中,节点只会随机向少数几个节点发送消息,消息最终是通过多个轮次的散播而到达全网的,因此使用 Gossip 协议会造成不可避免的消息延迟。不适合用在对实时性要求较高的场景下。
- 消息冗余 Gossip 协议规定,节点会定期随机选择周围节点发送消息,而收到消息的节点也会重复该步骤,因此就不可避免的存在消息重复发送给同一节点的情况,造成了消息的冗余,同时也增加了收到消息的节点的处理压力。而且,由于是定期发送,因此,即使收到了消息的节点还会反复收到重复消息,加重了消息的冗余。
Redis Cluster的Gossip机制
Redis Cluster 是在 3.0 版本引入集群功能。为了让让集群中的每个实例都知道其他所有实例的状态信息,Redis 集群规定各个实例之间按照 Gossip 协议来通信传递信息。

上图展示了主从架构的 Redis Cluster 示意图,其中实线表示节点间的主从复制关系,而虚线表示各个节点之间的 Gossip 通信。
Redis Cluster 中的每个节点都维护一份自己视角下的当前整个集群的状态,主要包括:
- 当前集群状态
- 集群中各节点所负责的 slots信息,及其migrate状态
- 集群中各节点的master-slave状态
- 集群中各节点的存活状态及怀疑Fail状态
Redis Cluster 的节点之间会相互发送多种消息,较为重要的如下所示:
| 消息 | 说明 |
| meet | 通过「cluster meet ip port」命令,已有集群的节点会向新的节点发送邀请,加入现有集群,然后新节点就会开始与其他节点进行通信 |
| ping | 节点按照配置的时间间隔向集群中其他节点发送 ping 消息,消息中带有自己的状态,还有自己维护的集群元数据,和部分其他节点的元数据 |
| pong | 返回ping和meet,包含自己的状态和其他信息,也可以用于信息广播和更新 |
| fail | 某个节点判断另一个节点fail之后,就发送fail给其他节点,通知其他节点,指定的节点宕机了 |
通过上述这些消息,集群中的每一个实例都能获得其它所有实例的状态信息。这样一来,即使有新节点加入、节点故障、Slot 变更等事件发生,实例间也可以通过 PING、PONG 消息的传递,完成集群状态在每个实例上的同步。
通过上述这些消息,集群中的每一个实例都能获得其它所有实例的状态信息。这样一来,即使有新节点加入、节点故障、Slot 变更等事件发生,实例间也可以通过 PING、PONG 消息的传递,完成集群状态在每个实例上的同步。下面,我们依次来看看几种常见的场景:
定时ping/pong消息
Redis Cluster 中的节点都会定时地向其他节点发送 PING 消息,来交换各个节点状态信息,检查各个节点状态,包括在线状态、疑似下线状态 PFAIL 和已下线状态 FAIL。
Redis 集群的定时 PING/PONG 的工作原理可以概括成两点:
- 一是,每个实例之间会按照一定的频率,从集群中随机挑选一些实例,把 PING 消息发送给挑选出来的实例,用来检测这些实例是否在线,并交换彼此的状态信息。PING 消息中封装了发送消息的实例自身的状态信息、部分其它实例的状态信息,以及 Slot 映射表。
- 二是,一个实例在接收到 PING 消息后,会给发送 PING 消息的实例,发送一个 PONG 消息。PONG 消息包含的内容和 PING 消息一样。
下图显示了两个实例间进行 PING、PONG 消息传递的情况,其中实例一为发送节点,实例二是接收节点

新节点上线
Redis Cluster 加入新节点时,客户端需要执行 CLUSTER MEET 命令,如下图所示。
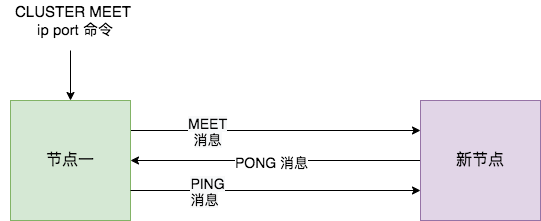
节点一在执行 CLUSTER MEET 命令时会首先为新节点创建一个 clusterNode 数据,并将其添加到自己维护的 clusterState 的 nodes 字典中。有关 clusterState 和 clusterNode 关系,我们在最后一节会有详尽的示意图和源码来讲解。
然后节点一会根据据 CLUSTER MEET 命令中的 IP 地址和端口号,向新节点发送一条 MEET 消息。新节点接收到节点一发送的MEET消息后,新节点也会为节点一创建一个 clusterNode 结构,并将该结构添加到自己维护的 clusterState 的 nodes 字典中。
接着,新节点向节点一返回一条PONG消息。节点一接收到节点B返回的PONG消息后,得知新节点已经成功的接收了自己发送的MEET消息。
最后,节点一还会向新节点发送一条 PING 消息。新节点接收到该条 PING 消息后,可以知道节点A已经成功的接收到了自己返回的P ONG消息,从而完成了新节点接入的握手操作。
MEET 操作成功之后,节点一会通过定时 PING 机制将新节点的信息发送给集群中的其他节点,让其他节点也与新节点进行握手,最终,经过一段时间后,新节点会被集群中的所有节点认识。
节点疑似下线和真正下线
Redis Cluster 中的节点会定期检查已经发送 PING 消息的接收方节点是否在规定时间 ( cluster-node-timeout ) 内返回了 PONG 消息,如果没有则会将其标记为疑似下线状态,也就是 PFAIL 状态,如下图所示。

然后,节点一会通过 PING 消息,将节点二处于疑似下线状态的信息传递给其他节点,例如节点三。节点三接收到节点一的 PING 消息得知节点二进入 PFAIL 状态后,会在自己维护的 clusterState 的 nodes 字典中找到节点二所对应的 clusterNode 结构,并将主节点一的下线报告添加到 clusterNode 结构的 fail_reports 链表中。

随着时间的推移,如果节点十 (举个例子) 也因为 PONG 超时而认为节点二疑似下线了,并且发现自己维护的节点二的 clusterNode 的 fail_reports 中有半数以上的主节点数量的未过时的将节点二标记为 PFAIL 状态报告日志,那么节点十将会把节点二将被标记为已下线 FAIL 状态,并且节点十会立刻向集群其他节点广播主节点二已经下线的 FAIL 消息,所有收到 FAIL 消息的节点都会立即将节点二状态标记为已下线。如下图所示。
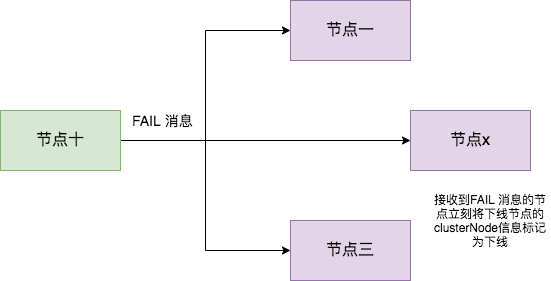
需要注意的是,报告疑似下线记录是由时效性的,如果超过 cluster-node-timeout *2 的时间,这个报告就会被忽略掉,让节点二又恢复成正常状态。
参考
https://zhuanlan.zhihu.com/p/41228196
https://www.cnblogs.com/yufeng218/p/13688582.html


