基础
哈希表
哈希表(散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做哈希(散列)函数,存放记录的数组叫做哈希(散列)表。
golang中的map是基于哈希表(也被称为散列表)实现的,所以,要进一步理解map的实现,就需要对哈希表有一定的了解。
学习哈希表首先要理解两个概念:哈希函数和哈希冲突
哈希函数
哈希函数(常被称为散列函数)是可以用于将任意大小的数据映射到固定大小值的函数,常见的包括MD5、SHA系列等。
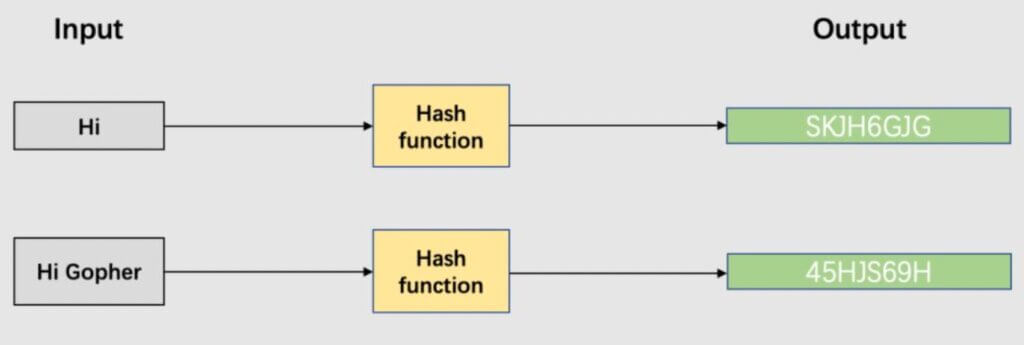
一个设计优秀的哈希函数应该包含以下特性:
- 均匀性:一个好的哈希函数应该在其输出范围内尽可能均匀地映射,也就是说,应以大致相同的概率生成输出范围内的每个哈希值。
- 效率高:哈希效率要高,即使很长的输入参数也能快速计算出哈希值。
- 可确定性:哈希过程必须是确定性的,这意味着对于给定的输入值,它必须始终生成相同的哈希值。
- 雪崩效应:微小的输入值变化也会让输出值发生巨大的变化。
- 不可逆:从哈希函数的输出值不可反向推导出原始的数据。
哈希冲突
哈希函数是将任意大小的数据映射到固定大小值的函数,但即使哈希函数设计得足够优秀,几乎每个输入值都能映射为不同的哈希值,当输入数据足够大,大到能超过固定大小值的组合能表达的最大数量数,冲突将不可避免!
如何解决哈希冲突
比较常用的Has冲突解决方案有链地址法和开放寻址法。
在讲链地址法之前,先说明两个概念:
- 哈希桶。哈希桶(也称为槽,类似于抽屉原理中的一个抽屉)可以先简单理解为一个哈希值,所有的哈希值组成了哈希空间。
- 装载因子。装载因子是表示哈希表中元素的填满程度。它的计算公式:装载因子=填入哈希表中的元素个数/哈希表的长度。装载因子越大,填入的元素越多,空间利用率就越高,但发生哈希冲突的几率就变大。反之,装载因子越小,填入的元素越少,冲突发生的几率减小,但空间浪费也会变得更多,而且还会提高扩容操作的次数。装载因子也是决定哈希表是否进行扩容的关键指标。
链地址法
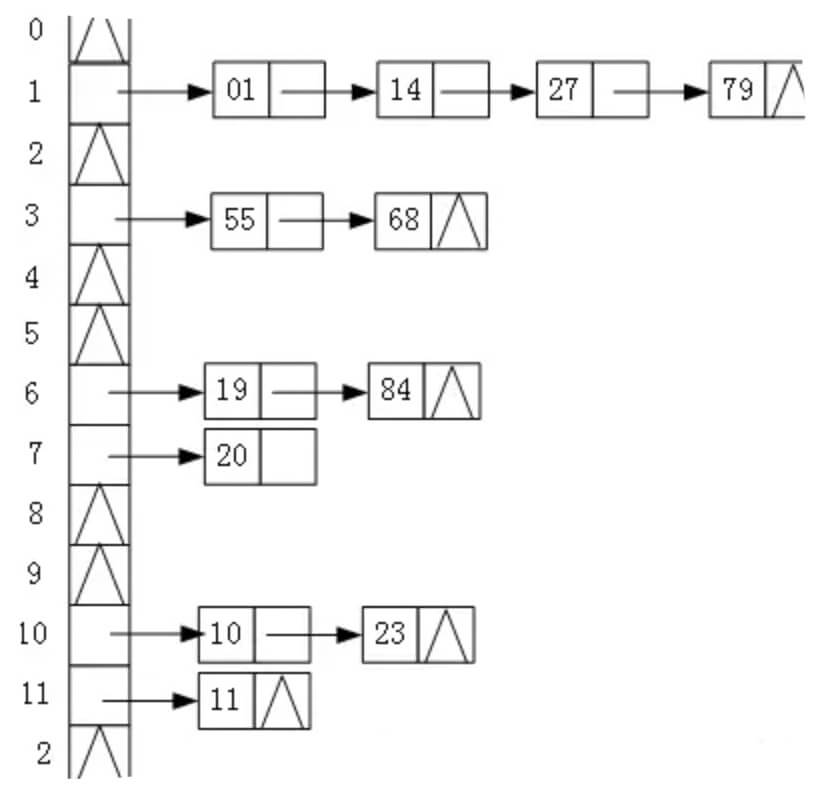
将所有哈希地址相同的都链接在同一个链表中 ,因而查找、插入和删除主要在同义词链中进行。链地址法适用于经常进行插入和删除的情况。例如有一组关键字为{19,14,23,01,68,20,84,27,55,11,10,79},其哈希函数为:H(key)=key MOD 13,使用链地址法所构建的哈希表如下图 所示:
开放寻址法
对于链地址法而言,槽位数m与键的数目n是没有直接关系的。但是对于开放寻址法而言,所有的元素都是存储在Hash表当中的,所以无论任何时候都要保证哈希表的槽位数m大于或等于键的数据n(必要时,需要对哈希表进行动态扩容)。
例如,在长度为 11 的哈希表中已填写好 17、60 和 29 这 3 个数据(如图(a) 所示),其中采用的哈希函数为:H(key)=key MOD 11,现有第 4 个数据 38 ,当通过哈希函数求得的哈希地址为 5,与 60 冲突,则分别采用以上 3 种方式求得插入位置如图 (b)所示:
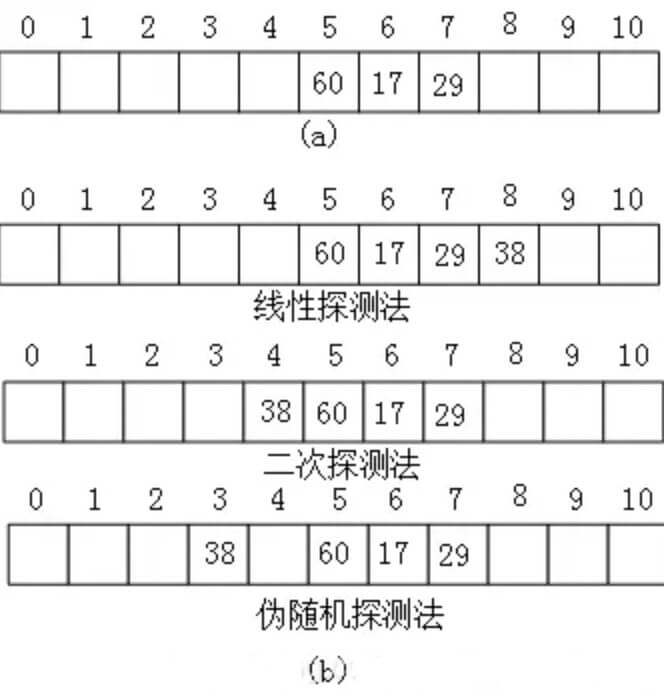
注释:在线性探测法中,当遇到冲突时,从发生冲突位置起,每次 +1,向右探测,直到有空闲的位置为止;二次探测法中,从发生冲突的位置起,按照 +12,-12,+22,…如此探测,直到有空闲的位置;伪随机探测,每次加上一个随机数,直到探测到空闲位置结束。
两种解决方案比较
对于开放寻址法而言,它只有数组一种数据结构就可完成存储,继承了数组的优点,对CPU缓存友好,易于序列化操作。但是它对内存的利用率不如链地址法,且发生冲突时代价更高。当数据量明确、装载因子小,适合采用开放寻址法。
链表节点可以在需要时再创建,不必像开放寻址法那样事先申请好足够内存,因此链地址法对于内存的利用率会比开方寻址法高。链地址法对装载因子的容忍度会更高,并且适合存储大对象、大数据量的哈希表。而且相较于开放寻址法,它更加灵活,支持更多的优化策略,比如可采用红黑树代替链表。但是链地址法需要额外的空间来存储指针。
Go Map实现
map中的数据被存放于一个数组中的,数组的元素是桶(bucket),每个桶至多包含8个键值对数据。哈希值低位(low-order bits)用于选择桶,哈希值高位(high-order bits)用于在一个独立的桶中区别出键。哈希值高低位示意图如下:

数据结构
src/runtime/map.go
// A header for a Go map.
type hmap struct {
count int // 代表哈希表中的元素个数,调用len(map)时,返回的就是该字段值。
flags uint8 // 状态标志,下文常量中会解释四种状态位含义。
B uint8 // buckets(桶)的对数log_2(哈希表元素数量最大可达到装载因子*2^B)
noverflow uint16 // 溢出桶的大概数量
hash0 uint32 // 哈希种子
buckets unsafe.Pointer // 指向buckets数组的指针,数组大小为2^B,如果元素个数为0,它为nil
oldbuckets unsafe.Pointer // 如果发生扩容,oldbuckets是指向老的buckets数组的指针,老的buckets数组大小是新的buckets的1/2。非扩容状态下,它为nil
nevacuate uintptr // 表示扩容进度,小于此地址的buckets代表已搬迁完成
extra *mapextra // 这个字段是为了优化GC扫描而设计的。当key和value均不包含指针,并且都可以inline时使用。extra是指向mapextra类型的指针
}
type mapextra struct {
// 如果 key 和 value 都不包含指针,并且可以被 inline(<=128 字节)
// 就使用 hmap的extra字段 来存储 overflow buckets,这样可以避免 GC 扫描整个 map
// 然而 bmap.overflow 也是个指针。这时候我们只能把这些 overflow 的指针
// 都放在 hmap.extra.overflow 和 hmap.extra.oldoverflow 中了
// overflow 包含的是 hmap.buckets 的 overflow 的 buckets
// oldoverflow 包含扩容时的 hmap.oldbuckets 的 overflow 的 bucket
overflow *[]*bmap
oldoverflow *[]*bmap
// 指向空闲的 overflow bucket 的指针
nextOverflow *bmap
}
// A bucket for a Go map.
type bmap struct {
// tophash包含此桶中每个键的哈希值最高字节(高8位)信息(也就是前面所述的high-order bits)
// 如果tophash[0] < minTopHash,tophash[0]则代表桶的搬迁(evacuation)状态
tophash [bucketCnt]uint8
}
bmap也就是bucket(桶)的内存模型图解如下:
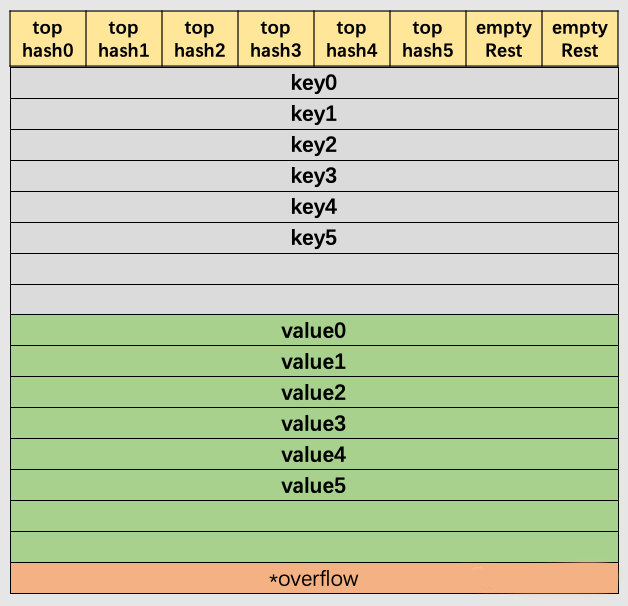
以上图解可看出,key和value是各自存储起来的,而非key/value/key/value…的形式。这样做的好处是能让我们消除例如map[int64]int所需要的填充。此外,在8个键值对数据后面有一个overflow指针,因为桶中最多只能装8个键值对,如果有多余的键值对落到了当前桶,那么就需要再构建一个桶(称为溢出桶),通过overflow指针链接起来。
重要常量
const (
// 一个桶中最多能装载的键值对(key-value)的个数为2^3=8
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
// 触发扩容的装载因子为13/2=6.5
loadFactorNum = 13
loadFactorDen = 2
// 键和值超过128个字节,就会被转换为指针
maxKeySize = 128
maxElemSize = 128
// 数据偏移量应该是bmap结构体的大小,它需要正确地对齐。
// 对于amd64p32而言,这意味着:即使指针是32位的,也是64位对齐。
dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)
// 每个桶(如果有溢出,则包含它的overflow的链接桶)在搬迁完成状态(evacuated* states)下,要么会包含它所有的键值对,要么一个都不包含(但不包括调用evacuate()方法阶段,该方法调用只会在对map发起write时发生,在该阶段其他goroutine是无法查看该map的)。简单的说,桶里的数据要么一起搬走,要么一个都还未搬。
// tophash除了放置正常的高8位hash值,还会存储一些特殊状态值(标志该cell的搬迁状态)。正常的tophash值,最小应该是5,以下列出的就是一些特殊状态值。
emptyRest = 0 // 表示cell为空,并且比它高索引位的cell或者overflows中的cell都是空的。(初始化bucket时,就是该状态)
emptyOne = 1 // 空的cell,cell已经被搬迁到新的bucket
evacuatedX = 2 // 键值对已经搬迁完毕,key在新buckets数组的前半部分
evacuatedY = 3 // 键值对已经搬迁完毕,key在新buckets数组的后半部分
evacuatedEmpty = 4 // cell为空,整个bucket已经搬迁完毕
minTopHash = 5 // tophash的最小正常值
// flags
iterator = 1 // 可能有迭代器在使用buckets
oldIterator = 2 // 可能有迭代器在使用oldbuckets
hashWriting = 4 // 有协程正在向map写人key
sameSizeGrow = 8 // 等量扩容
// 用于迭代器检查的bucket ID
noCheck = 1<<(8*sys.PtrSize) - 1
)
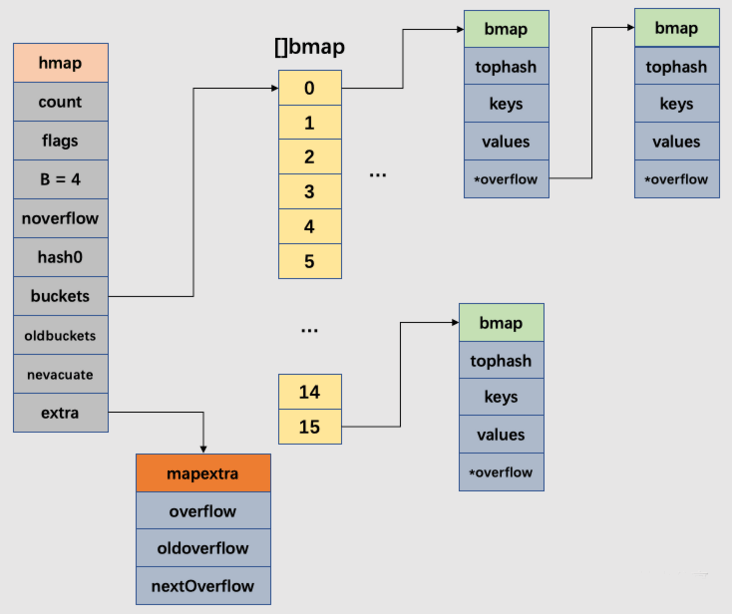
综上,我们以B等于4为例,展示一个完整的map结构图:
相关链接
https://mp.weixin.qq.com/s/OHROn0ya_nWR6qkaSFmacw


