因为中文字符的特殊性,基本上各类语言对于中文字符都需要进行特定的处理。
原理说明
golang中,字符串的底层是通过byte数组来实现的, 我们看下byte的底层结构:
type byte = uint8
可以看到,byte类型的底层实际为uint8类型
而字符串的底层结构为:
type StringHeader struct {
Data uintptr // 指向底层字节数组的指针
Len int // 字符串的字节长度
}
由于golang默认为UTF-8编码,所以,中文进行存储时,如“你好”,会存储为:

“你”编码为\xe4\xbd\xa0,“好”编码为\xe5\xa5\xbd
rune类型底层结构:
type rune = int32
rune类型是int32的别名(-231~231-1),对于byte(-128~127),可表示的字符更多。由于rune可表示的范围更大,所以能处理一切字符,当然也包括中文字符。在平时计算中文字符,可用rune。
byte 与 rune对比
func TestOther(t *testing.T) {
text := "abcd1234浮生无事"
fmt.Println([]byte(text))
fmt.Println([]rune(text))
}
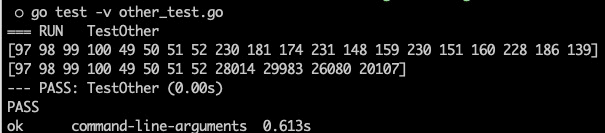
通过上面的例子,我们可以直观的看到,rune将字符串拆分为多个Unicode 字符序列,而byte则将其拆分为字节序列。
所以,利用rune就可以解决各类中文字符串计算问题。
中文字符串处理
func TestOther(t *testing.T) {
text := "abcd1234浮生无事"
textLen := len(text)
t.Log("len:" + strconv.FormatInt(int64(textLen), 10))
for i := 0; i <= textLen - 1; i++ {
t.Log(fmt.Sprintf("word:%s", text[i:i+1]))
}
}
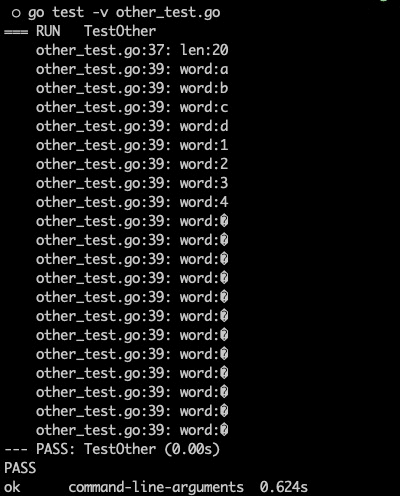
可以看到,因为字符串计算是按照字节来计算的,所以,无论是字符串长度,还是字符串切割,都是按照字节来进行,导致中文乱码(注意在golang中一个汉字占3个byte)。
此时,为解决该类情况,正确的对中文进行处理:
func TestOther(t *testing.T) {
text := "abcd1234浮生无事"
textRune := []rune(text)
textLen := len(textRune)
t.Log("len:" + strconv.FormatInt(int64(textLen), 10))
for i := 0; i < textLen; i++ {
t.Log(fmt.Sprintf("word:%s", string(textRune[i])))
}
}
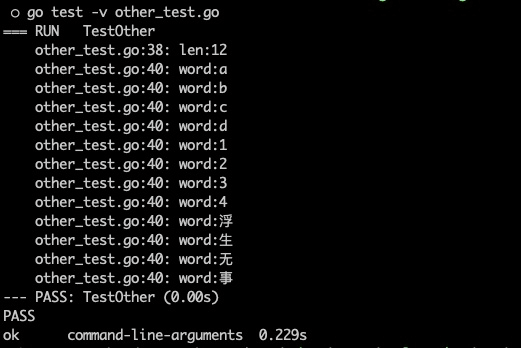
将字符串,转为[]rune类型后,即可以对中文字符进行正确的处理,不会出现乱码。


